南湖新闻网讯(通讯员 苏桂新)近日,自然语言处理领域顶级国际会议ACL 2024 (The 62nd Annual Meeting of the Association for Computational Linguistics,CCF-A类) 录用了信息学院沙灜教授课题组在自然语言处理领域的2篇研究工作。
沙灜教授课题组被录用的2篇研究论文分别以“A Unified Generative Framework for Bilingual Euphemism Detection and Identification”和“Refine, Align, and Aggregate: Multi-view Linguistic Features Enhancement for Aspect Sentiment Triplet Extraction”为题,分别研究统一建模委婉语检测和委婉语识别任务以及探索多视角语言特征对方面情感三元组抽取的先验指示作用。
委婉语是指通过使用间接或隐晦的语言来表达思想或传递信息的语言形式。为了避免明确表达不友好的观点或言论,一些用户选择使用委婉语来掩盖歧视性、侮辱性或不公平的言论。因此,委婉语的检测和识别研究对于及时发现和干预委婉语的传播具有重要意义。然而,现有的委婉语数据集局限于特定领域或特定语言,且研究工作缺乏对委婉语检测和识别的统一建模。
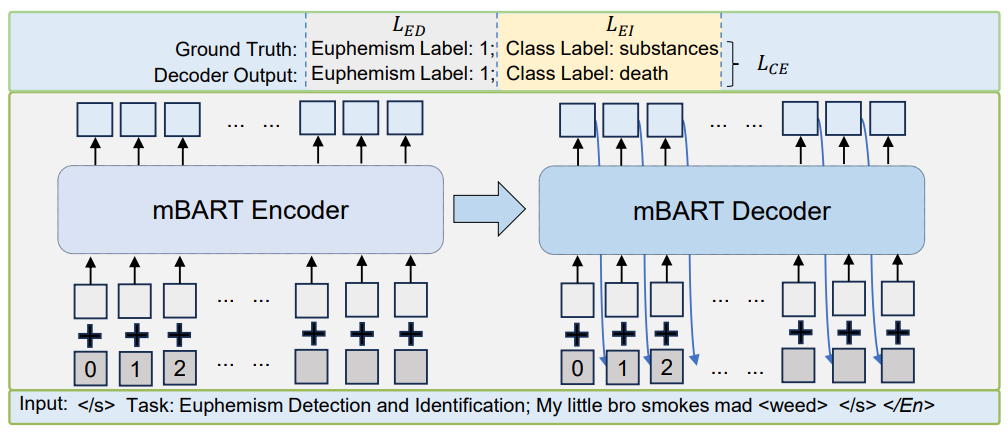
基于此,沙灜教授研究团队构建了一个涵盖汉语和英语两种语言共12个类别的大规模双语多类别委婉语数据集BME,同时提出生成模型JointEDI来统一建模双语委婉语检测和识别任务。通过与大语言模型 (LLMs) 和人工评估的比较,实验结果验证了JointEDI模型的有效性以及将委婉语检测和委婉语识别任务统一建模的可行性。此外,BME数据集还为委婉语检测和委婉语识别提供了新的参考标准。
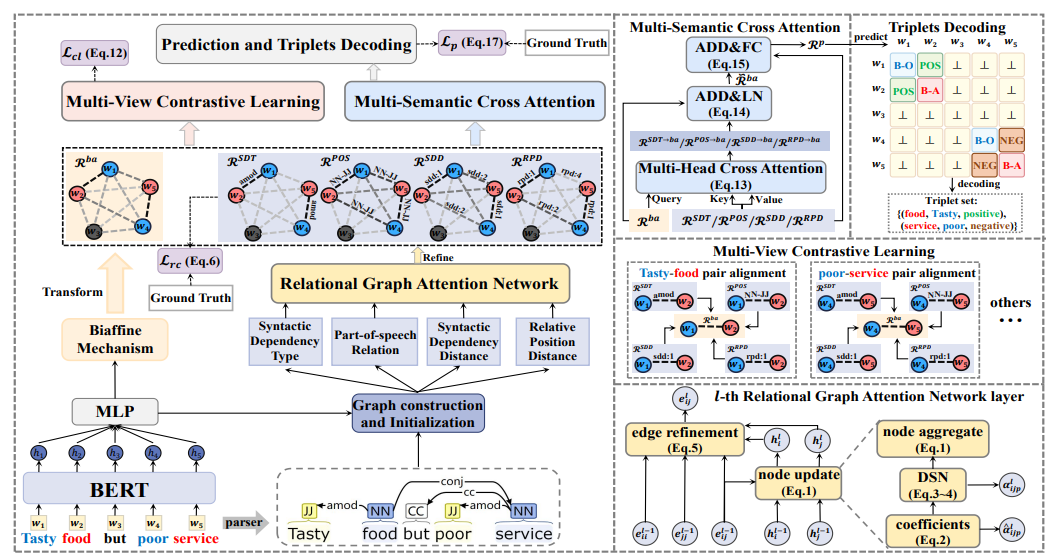
方面情感三元组抽取是方面级情感分析领域中具有挑战性的信息抽取式任务,旨在从给定评论文本中抽取出所有方面词 (aspect term) 和观点词 (opinion term),并预测匹配的方面词和观点词对之间的情感极性 (sentiment polarity),从而构成情感三元组,该研究对于产品优化、内容推荐和舆情分析等方面具有重要意义。以往基于不同范式建模的研究工作往往忽略了多视角语言特征对情感三元组抽取的先验指示作用。基于此,沙灜教授研究团队提出多视角语言特征增强框架 (Multi-view Linguistic Features Enhancement, MvLFE),以“精细,对齐和聚合”(Refine, Align, and Aggregate)的学习过程来探索挖掘不同语言特征的先验指示作用。MvLFE模型首先采用关系图注意力网络 (relational graph attention network) 来表征并精细不同视角语言特征所表示的词对关系,随后采用多视角对比学习 (multi-view contrastive learning) 将不同语言特征在情境语义空间中进行细粒度对齐以保持语义一致性。最后采用多语义交叉注意力 (multi-semantic cross attention) 将不同语言特征进行聚合以捕获它们之间互补的高阶交互。实验结果验证了MvLFE模型的有效性和鲁棒性,在多个基准数据集上与以往基线方法对比取得了SOTA性能表现。
ACL (Annual Meeting of the Association for Computational Linguistics,国际计算语言学年会) 是计算语言学和自然语言处理领域中影响力最大的国际顶级学术会议,由国际计算语言学协会组织,每年召开一次,在中国计算机学会(CCF) 推荐会议列表中被列为A类会议。沙灜教授课题组被录用的2篇研究工作中,信息学院博士研究生胡玉雪、本科生李俊松和博士研究生王同官为委婉语检测和识别研究论文的共同第一作者,硕士研究生苏桂新为情感分析研究论文的第一作者,沙灜教授皆为两篇论文的通讯作者。上述研究工作获得了国家自然科学基金面上项目等的资助。
审核:沙灜