南湖新闻网讯(通讯员 肖云浩 )近日,我校信息学院智能化软件团队在Web智能领域国际会议The Web Conference 2026 (TheWebConf ’26,CCF-A类) 发表题为“A Unified and Time-Efficient Multi-Agent Framework for Data Discovery”的研究论文。该研究针对海量Web表格数据发现面临的“效率”与“精度”难以兼得的根本性挑战,创新性提出一种基于多智能体协同的统一框架,为大规模数据湖中的数据集成提供新的解决方案。
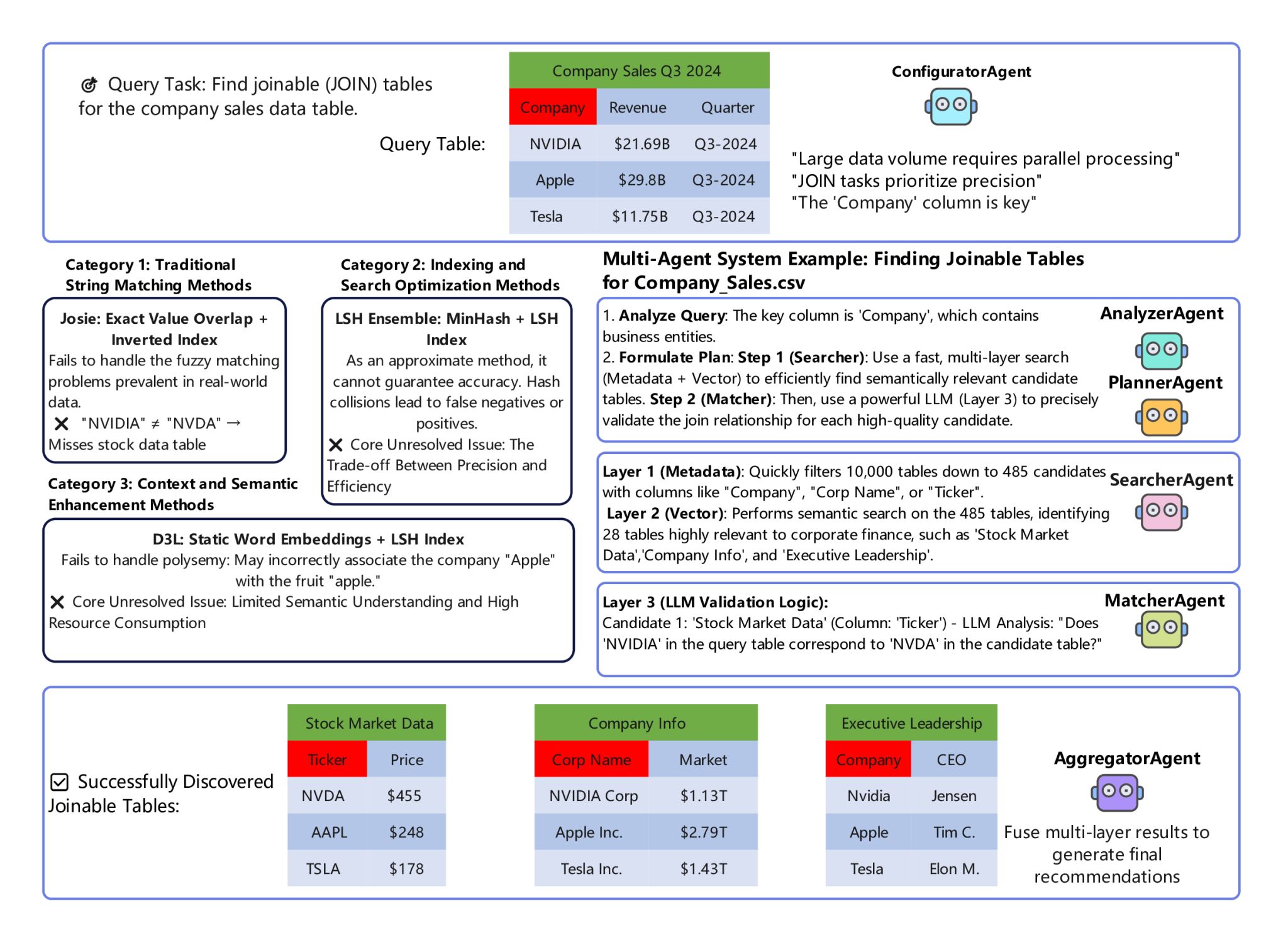
图1 多智能体协同框架与三层级联过滤(TLCF)架构图
在Web大数据时代,从数十亿个HTML表格和开放数据集中发现可连接(Joinable)或可并集(Unionable)的表格,是数据分析和知识发现的关键步骤。然而现有单一策略方法往往顾此失彼,传统字符串匹配方法处理速度快但无法识别语义变体(如无法将“NVIDIA”与“NVDA”关联);而基于深度学习的方法虽准确但计算成本过高,难以应对海量数据。
为解决上述问题,信息学院智能化软件团队设计出一个包含配置智能体、规划智能体、分析智能体、搜索智能体、匹配智能体和聚合智能体等6大专业智能体协作系统。该系统由LangGraph工作流引擎编排,能根据任务类型(Join或Union)动态调整执行策略。该研究核心突破在于提出“三层级联过滤”(Three-Layer Cascaded Filtering, TLCF)算法。该算法第一层利用元数据进行快速粗筛,第二层利用向量搜索进行语义召回,第三层则引入大语言模型(LLM)进行高精度上下文推理验证。
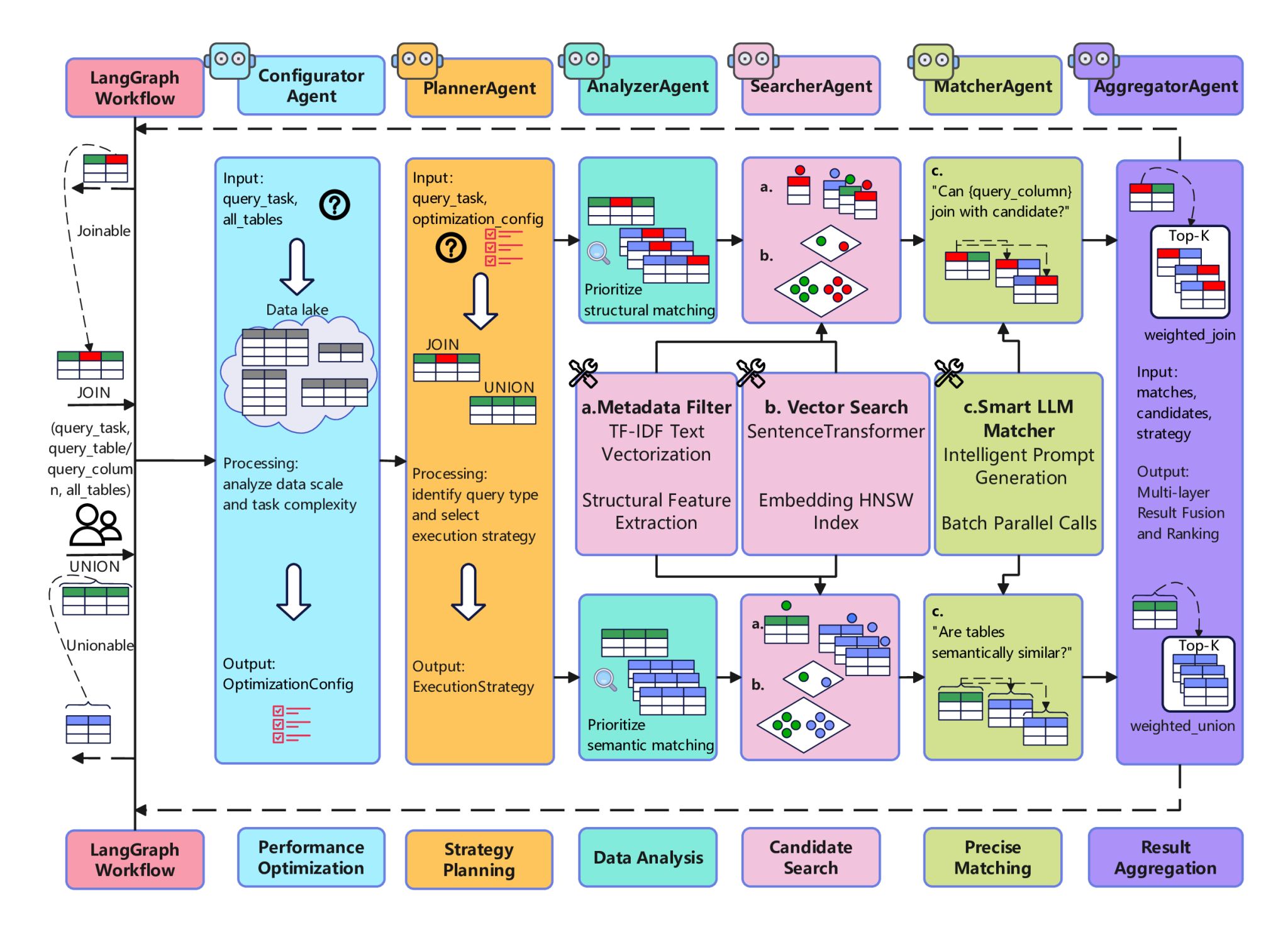
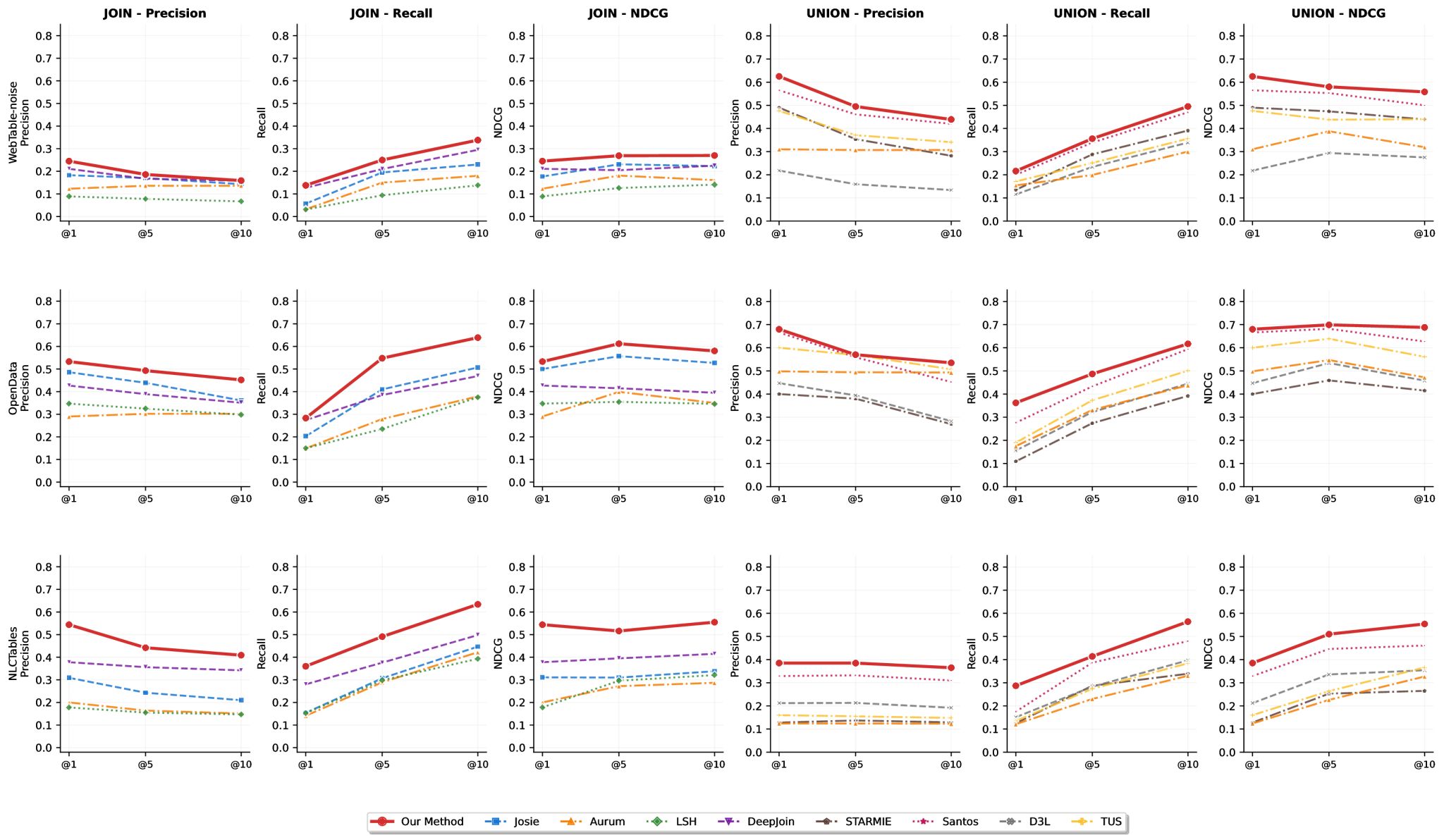
图2 本研究提出的方法与各类基准方法在三个数据集上的性能对比
研究团队在包含噪声的真实Web数据(WebTable-noise)、政府开放数据(OpenData)以及自然语言查询的表格数据集(NLCTables)3个多样化数据集上进行广泛实验。结果显示(图3),该框架在Join和Union两类任务所有关键指标(Precision, Recall, NDCG)上均显著优于DeepJoin、Santos、Starmie等现有最先进方法。特别是在处理含有大量拼写错误和格式差异的噪声数据时,该框架凭借LLM的深度推理能力,展现出卓越鲁棒性。此外,成本分析表明,通过使用Gemini 1.5 Flash等轻量级模型,该系统在保持高精度同时,可将计算成本控制在极低水平,具备极高应用推广价值。
综上,该研究不仅解决了长期困扰Web数据集成领域的效率-精度权衡问题,也为利用多智能体系统解决大规模信息检索任务提供了新范式。该论文方法可用于互联网上进行农业生物结构化数据的自动搜索整合,为进一步数据分析和知识发现提供支持。该方法已集成至华中农业大学“华农智能体”,供科研工作者免费使用。
信息学院冯在文副教授和李小霞副教授为该论文共同通讯作者,硕士研究生肖云浩和青年教师王颖为论文共同第一作者。
审核|李小霞



 最近新闻
最近新闻