南湖新闻网讯(通讯员 何林)近日,我校果蔬园艺作物种质创新与利用全国重点实验室、药用植物资源可持续利用团队梅之南教授和杨庆勇教授课题组合作研究成果以“AMIR: a multi-omics data platform for Asteraceae plants genetics and breeding research”为题在Nucleic Acids Research发表。研究构建了一个集数据整合、分析和可视化为一体的菊科植物的多组学数据库——Asteraceae Multi-omics Information Resource(AMIR)(AMIR数据库链接:https://yanglab.hzau.edu.cn/AMIR),助力菊科植物的功能基因研究与育种策略优化。
菊科植物是被子植物中的一个重要类群,包含许多重要的经济的作物,如油料作物向日葵、蔬菜莴苣、花卉万寿菊和药用植物艾、黄花蒿、苍术、菊花等。然而,由于菊科植物基因组复杂,并且缺乏相关数据的整合和便利的分析工具,导致菊科植物的后基因组时代研究耗时耗力。该研究发布的AMIR数据库整合了菊科74种个物种的多组学数据,涵盖132个基因组、3897个转录组样本、超过4276万个变异数据及1.5万多个代谢物基因注释,所有的数据资源经统一处理,标准化进行整合。同时数据库包含了基因组和基因注释、泛基因组和跨物种比较、转录组分析、遗传变异和关联分析、代谢途径和基因调控网络和工具集成与数据下载六大板块;这些功能帮助研究人员快速分析基因之间的关联、挖掘重要性状相关的候选基因,解读菊科植物中的重要代谢途径。
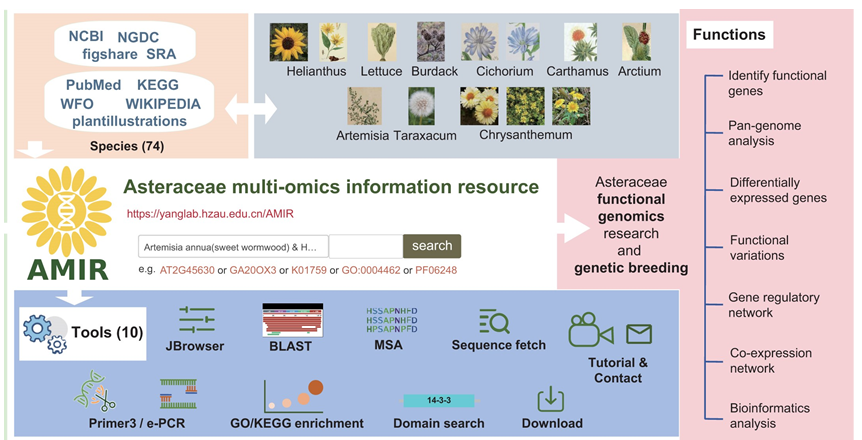
利用AMIR数据库及分析平台,研究人员发现3-羟基-3-甲基戊二酰辅酶A还原酶(HMGR)基因在43种菊科植物中保守,同时获得了不同菊科物种中HMGR基因的保守区域和进化关系,为进一步研究其在菊科植物代谢中的作用提供数据支持。在AMIR平台的差异表达分析模块中,研究人员通过分析不同实验条件下的基因表达差异、利用GO/KEGG富集分析工具,揭示了与植物防御机制相关的代谢通路;这一功能展示了AMIR数据库在植物病害研究和抗病育种中的潜力。此外,通过AMIR数据库中的SNP和InDel变异模块,研究人员可以查找特定基因的遗传变异情况,并分析变异与基因表达之间的关系。该模块支持研究人员进行基因组水平的关联分析,以发现与特定耐逆性状或药用成分合成相关的候选基因,为菊科植物分子标记辅助育种提供了重要工具。
我校信息学院博士后刘东旭、博士研究生罗诚方、陈翔、毛红霞、李嘉炜、张林娜,硕士研究生戴睿、黄小燕,植物科学技术学院博士研究生何林共同完成了数据库的相关工作。果蔬园艺作物种质创新与利用全国重点实验室、药用植物资源可持续利用团队梅之南教授和杨庆勇教授为该论文的共同通讯作者。该研究得到了国家重点研发计划项目;国家自然科学基金项目、湖北省种业高质量发展项目以及华中农大中央高校基本科研业务费专项资金等多个项目的资助,华中农业大学作物遗传改良国家重点实验室的生物信息学计算平台支持。
审核人:梅之南
论文链接:https://doi.org/10.1093/nar/gkae833
英文摘要:
As the largest family of dicotyledon, the Asteraceae family comprises a variety of economically important crops, ornamental plants and numerous medicinal herbs. Advancements in genomics and transcriptomic have revolutionized research in Asteraceae species, generating extensive omics data that necessitate an efficient platform for data integration and analysis. However, existing databases face challenges in mining genes with specific functions and supporting cross-species studies. To address these gaps, we introduce the Asteraceae Multi-omics Information Resource (AMIR; https://yanglab.hzau.edu.cn/AMIR/), a multi-omics hub for the Asteraceae plant community. AMIR integrates diverse omics data from 74 species, encompassing 132 genomes, 4 408 432 genes annotated across seven different perspectives, 3897 transcriptome sequencing samples spanning 131 organs, tissues and stimuli, 42 765 290 unique variants and 15 662 metabolites genes. Leveraging these data, AMIR establishes the first pan-genome, comparative genomics and transcriptome system for the Asteraceae family. Furthermore, AMIR offers user-friendly tools designed to facilitate extensive customized bioinformatics analyses. Two case studies demonstrate AMIR’s capability to provide rapid, reproducible and reliable analysis results. In summary, by integrating multi-omics data of Asteraceae species and developing powerful analytical tools, AMIR significantly advances functional genomics research and contributes to breeding practices of Asteraceae.



 最近新闻
最近新闻